The most unverified learning problem can be called Clustering. Like all other problem of similar nature, it focusses on exploring a structure in a compiled data that is unlabelled. A very novice definition of clustering would be the process by which organising objects into groups which has members that have similarities in some or the other way. Therefore, a cluster can be called as a compiled set of objects that are similar between themselves and different to those objects which belongs other groups. A simple graphical representation of this explanation could be as follows:
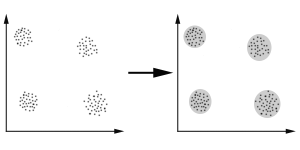
In this case, it can be easily identified that the data has been divided into 4clusters. This particular representation has classified data into exclusive clusters on the basis of the distance. Hence, it could be called as distance based clustering.
Another type of clustering would be conceptual clustering. In this type of clustering objects are classified and grouped in accordance with their fit to the descriptive concepts and not according to the simple similarity measures.
There are certain goals of clustering. These are to identify the intrinsic grouping in a set of data that is originally unlabelled. It is difficult to decide what constitutes a good clustering. It is sure that there cannot be an absolute best criterion which would be independent of the ultimate aim of clustering. It is mostly the user who decides and supplies the criterion as per the need and suitability of the study.
The application of clustering can be seen in various fields. The key areas where we often see the use of clustering are:
• Marketing: In the field of marketing clustering is done to identify customers with similar buying behaviour on the basis if the data showing their buying records.
• Biology: The classification of plants and animals, given their features.
• Insurance: Clustering insurance holders on the basis of high average claim cost and identifying the frauds.
• Other areas like City planning, Earthquake analysis and WWW are where cluster analysis has been found to have their place.
However, clustering does come with its own set of problems like it does not address all the requirements adequately and in a limited time frame, it becomes difficult to address large number of data items with complexity. Another problem with clustering is that the interpretation of clustering can be done in different ways so standardization in interpretation is difficult to achieve.